
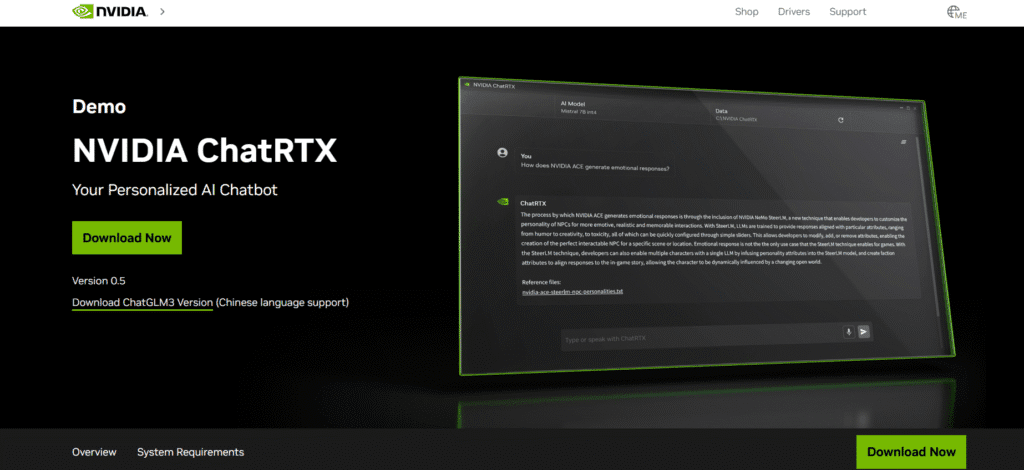
Chat with RTX (or ChatRTX) is a demo app by Nvidia.
It lets you run a personalized AI chatbot locally on your PC.
You feed it your files (docs, PDFs, YouTube transcripts) and it answers in context.
It uses retrieval augmented generation (RAG) + Nvidia’s TensorRT-LLM stack to run inference locally.
Because it’s local, your private files don’t need to go to servers.
Local file integration
You point Chat with RTX to folders of .txt, .pdf, .docx, .xml. It will index and query them.
YouTube / video transcript support
You can provide YouTube links; it will fetch transcripts and make them queryable.
Local inference using GPU
It uses your Nvidia GPU (RTX 30 / 40 series) + TensorRT optimizations to speed up chat.
Multiple LLM model support (bundled models)
It ships with Mistral 7B, and supports models like LLaMA 2.
Source attribution / context awareness
Replies come with references to documents.
Offline and privacy focus
Works without internet once set up and respects local data.
Chat with RTX is free to download it’s a demo / tech preview.
There is no public paid tier announced yet.
Your cost is your hardware (GPU, VRAM) and system resources.
You may pay indirectly if you use models that require more compute or GPU time.
Data never leaves your PC privacy is stronger
No cloud dependency or latency issues
You can query your own documents and videos
GPU acceleration means faster local inference
It’s free to try now
Requires strong hardware (GPU, memory)
Setup can be complex (dependencies, file indexing)
As a demo, features are limited and may be buggy
Model quality is bound by the shipped LLMs
Scaling to many files or large datasets may slow down
Start with a small folder of documents so indexing is manageable.
Use the YouTube transcript feature for videos you want to query.
Monitor GPU usage and VRAM so you don’t exceed hardware limits.
Test with simple queries first to verify context is loaded correctly.
Be careful giving it huge data sets performance may degrade.
Chat with RTX is a bold demonstration of what on device AI chat can do when paired with your own files.
It leans on terms like “local AI chatbot,” “GPU accelerated inference,” “file-powered AI,” “on-device LLM,” and “retrieval augmented generation.”
For now it’s free and demands good hardware.
Though public traffic and follower stats are not known, the demo’s privacy and offline promise makes it exciting.
If you weave in those competitor terms naturally, your article will be aligned with what users search for.
